
Reinforcement Learning with Unity ML Agents
A couple of years ago Unity started working on a framework, that would enable training machine learning algorithms in virtual environments: ML-Agents Toolkit. It is used by a number of companies across the world, including famous DeepMind, to aid research in computer vision and robotics in such tasks as autonomous driving.
In this post we present an example bot built with C# and TensorFlow framework, that learns to play a game in a simple Unity-based virtual environment using one of the state of the art reinforcement learning algorithms: soft actor-critic.
Contents
Running the sample
We will start by installing Unity and running the game.
NOTE: you can also run the learning algorithm without installing Unity. There’s a hardcoded
trivial environment, in which agent simply has to repeat the numbers it “sees”. Just skip
the Unity section in this post, and find the commented out RunRepeat method
in Program.cs in our sample code.
NOTE: this should work on Linux and MacOS, but we only tested on Windows. Please, report any issues to https://github.com/losttech/Gradient-Samples/issues
Getting Unity ML Agents
- Download and install Unity (free personal edition is enough)
- Install
Unity Editor 2019.3(Unity Hub ->Installs->Add-> Select2019.3-> no additional packages required)
NOTE: other Unity Editor versions and configurations (see below) might work too, but the one described here has been tested
- Clone ML-Agents: git clone –branch 0.13.1 https://github.com/Unity-Technologies/ml-agents.git
- Checkout branch 0.13.1 (if cloned from IDE)
- Open Unity Hub,
Projects, clickAdd, and openUnitySDKfolder from the repository you just cloned - In the Projects list, there is a column named “Unity Version”, which you need to set to 2019.3 for
UnitySDKproject
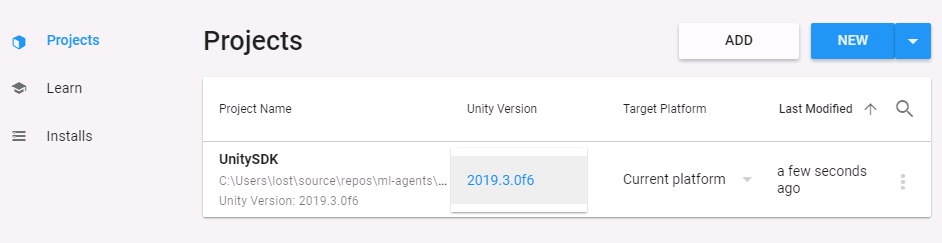
- Click on the project name to open it, and confirm you want to upgrade, BUT don’t allow using the new database version
- Hold on… x2
- Once Unity loads the project, find the
Projecttool window, and navigate toAssets\ML-Agents\Examples\3DBall\Scenes - Double-click the 3DBall scene to load it in the Editor
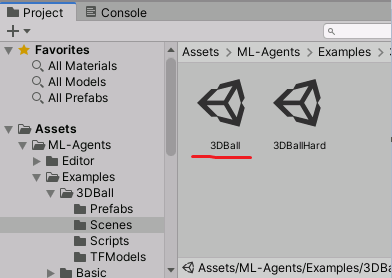
- Press
Playbutton at the top to run the scene - The environment will run, and you will see a sample agent made by Unity playing it
- Press
Playonce more to stop the environment
Get the sample agent source code based on Soft Actor Critic
- clone Gradient samples: https://github.com/losttech/Gradient-Samples.git
- (optionally) In IDE, open
Gradient-Samplessolution orRL-MLAgentsproject as startup
Run the sample agent
You don’t need a GPU to train this sample. An OK CPU should learn to play the game in under 15 minutes. However, if you want your system to be responsive during that time, pass a single command line parameter to the RL-MLAgents - the number of CPU cores you want it to use. We recommend to set it to 75% of your total CPU core count. Alternatively, you could try lowering the process priority after the launch.
NOTE: the first launch will take some time to download
and install TensorFlow runtime: ~300MB download, ~1GB after unpacking. If you already have
TensorFlow 1.15 installed, you can remove the dependency on LostTech.TensorFlow.Python package,
and use GradientEngine.UseEnvironment to point the sample to the preinstalled one.
- run RL-MLAgents project
- On Windows: allow firewall exception to let agent connect to Unity
- Switch back to Unity, and press
Playonce the program asks for it - Watch it wiggle the cubes erratically. It starts with random actions!

- after a certain time passes (just before replay buffer hits 2%) it will print a message on the console about switching to the learned agent policy
- Watch the agent gradually learn to joggle, until it never looses a ball!

Bot internals
The trainer is implemented in C#, and targets .NET Core 3.1. It uses our TensorFlow binding for .NET to build and train a neural network, and our binding to ML Agents to connect to Unity.
Interaction with Unity environment
Hopefully, in the future Unity will release a C# binding similar to their Python one. Meanwhile we made an unofficial one, and published it to NuGet.
There are 2 main classes, that are used in our bot to interact with Unity:
UnityEnvironment establishes connection to Unity, and allows you to control the game:
Reset() - restarts the game
Step() - advances the game one tick at a time
GetStepResult(string? agentGroupName): BatchedStepResult - returns what an agent group
“saw” during the last step
SetActions(string? agentGroupName, ndarray actions) - lets bot decide what it will do
during the next step
NOTE: ML-Agents support multiple agent groups in a single environment, which can be useful to have, for example, teams in a football game. 3DBall environment has only one group.
NOTE: ndarray is a multidimensional array class, that is heavily used in TensorFlow.
BatchedStepResult contains information about agent group observations during the last step. The result is “batched”, because a group can have multiple agents, so their observations are “batched” together. There are 12 agents in the default configuration of 3DBall environment.
It contains the following properties:
obs: ndarray[] - what agents actually saw in the environment
reward: ndarray - a reward, that agents got during the last tick (one per agent)
done: ndarray - 0 or 1, if the game is over for the specific agent (in 3DBall:
1 - if agent just lost the ball)
Extra
You can read the full documentation for ML-agents on the official site, but the classes and members above are enough to interact with many premade environments.
We also created a simple IEnvironment interface matching UnityEnvironment in case you want
to plug in environments of other kinds. Please see RepeatObservationEnvironment
for a trivial example:
/// <summary>
/// A simple environment, where agents simply have to repeat the same observation.
/// <para>(Do what Archimonde does anyone?)</para>
/// </summary>
class RepeatObservationEnvironment : IEnvironment {
float previousObservation;
float observation;
float[] action;
readonly Random random = new Random();
public RepeatObservationEnvironment(int agents) {
this.action = new float[agents];
}
public int AgentCount => this.action.Length;
public BatchedStepResult GetStepResult(string? agentGroupName) {
if (agentGroupName != null) throw new KeyNotFoundException();
var dimensions = new int[] {this.AgentCount, 1 };
var type = PythonClassContainer<float32>.Instance;
return new BatchedStepResult(
obs: new[] { np.ones(dimensions, dtype: type) * this.observation) },
reward: (ndarray)(2 - (ndarray.FromList(this.action) - this.previousObservation).__abs__()),
done: np.zeros(this.AgentCount),
// these have to be set to something
max_step: null,
agent_id: np.zeros(this.AgentCount),
action_mask: null);
}
public void Reset() {
this.observation = this.previousObservation = 0;
Array.Fill(this.action, 0);
}
public void SetActions(string? agentGroupName, ndarray actions) {
if (agentGroupName != null) throw new KeyNotFoundException();
for (int agentN = 0; agentN < this.action.Length; agentN++)
this.action[agentN] = (float32)actions[agentN, 0];
}
public void Step() {
this.previousObservation = this.observation;
this.observation = (float)this.random.NextDouble() * 2 - 1;
}
}
Soft Actor-Critic
Soft Actor-Critic is a state of the art algorithm for learning continuos control tasks, that was developed in 2018 in University of California, Berkley. The original paper with the full description is available on arXiv.org. Here we will provide short descriptions of its components, what they do, and how they learn.
Policy network
Policy network is a neural network, that takes in observations, and chooses the action the agent will take in the next time step.
In addition to learning the exact action network also learns how to randomize the action a little bit to allow bot to explore something it would not have tried otherwise.
In our example we use a simple fully connected network with 2 layers. This is the part of the algorithm you would have to enhance first to handle more complicated environments.
Q-networks
Q-networks get both the observation and the action (which is the output of the policy network), and try to guess the reward the agent will get for performing that action under the circumstances.
Replay buffer
Soft Actor-Critic does not learn after each example, as that might have caused catastrophic forgetting: learning to act with only recent experience would make bot completely forget how to get rare rewards it saw exploring the environment in the distant past.
So instead a large chunk of memory is used to store bot past experiences of game ticks. When enough new experience is collected, and it is time to train the bot’s networks, the training algorithm selects a small subset of random experiences from the buffer to train on.
A single “experience” in the buffer contains observations before and after the tick, the action bot tried to perform, and the reward it received.
Target and main
Training keeps 2 copies of actor-critic: “target” and “main”. During training “main” network uses “target”’s outputs as the baseline to estimate what would have happened. After each training episode, “target” network is changed slightly to be more like “main” one. This limits variability in predictions while the network is training to learn to predict in the first place:
tf.assign(v.target, v.target * polyak + v.main * (1-polyak), name: "targetUpdate")))
Training targets
Training process optimizes two targets:
- Q-loss: the difference between the real reward, and the predicted one.
- Pi-loss, that tunes the action randomizer to be closer to the expected best action.
All the targets and optimizers are defined here.
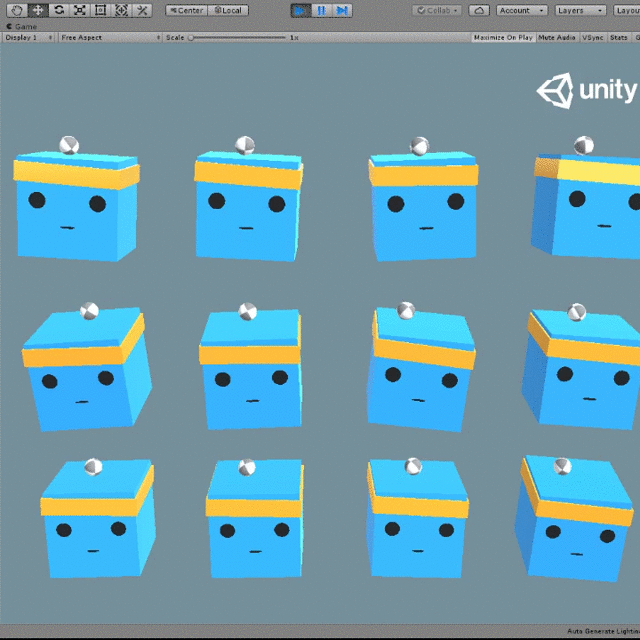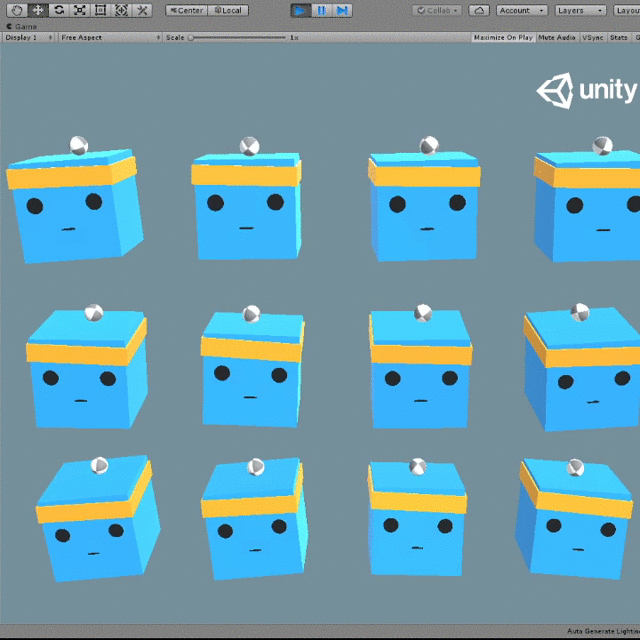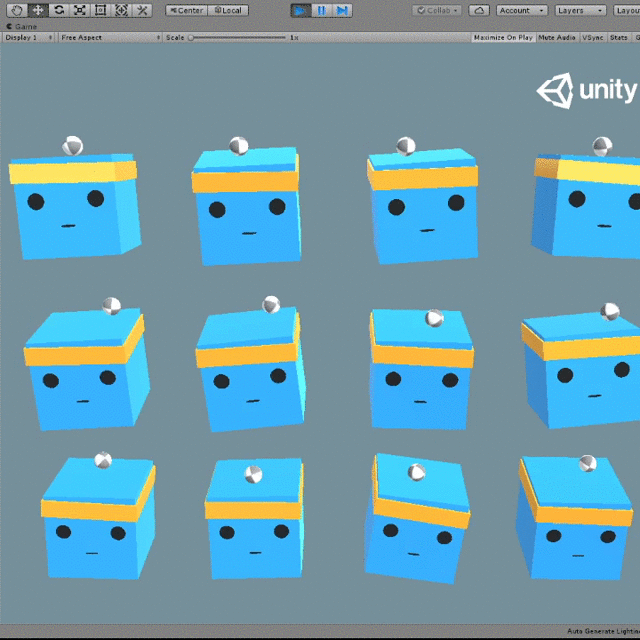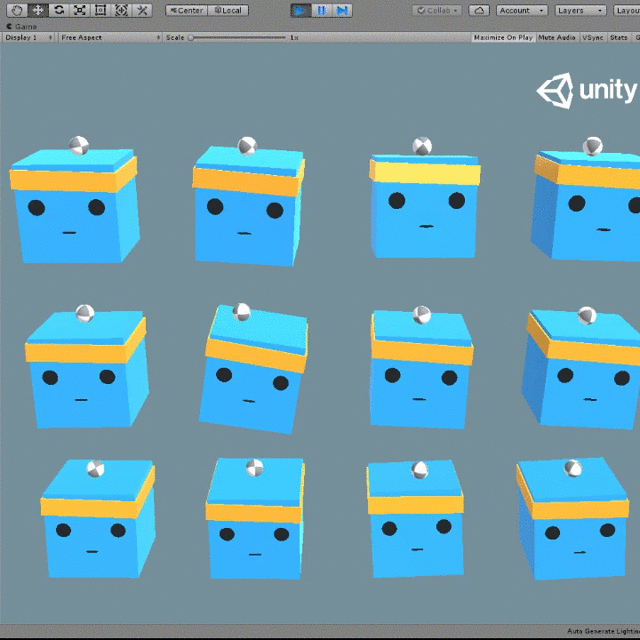
What’s next
Deal with wiggling
The bot trained using this sample shakes a lot. You can try to tweak training to minimize that. This would be a good first exercise with a visible impact.
TensorBoard and saving model
Our sample currently lacks any logging for TensorBoard, and saving the actual model, which we leave as an exercise for our readers. There is sample code doing it in another sample, GPT-2.
Keras APIs
The sample is written in TensorFlow 1.0 API style. Gradient supports TensorFlow 1.15, which has newer Keras APIs. Try converting the old style code into the new style.
Try on other environments
Try other Unity ML Agents environments, and see how actor-critic will perform there. You might need to tweak observation and action processing for that.
To use the trained model for an actual bot in a Unity game, please, refer to their documentation.
Tips for other tasks
If you want to start working on more complicated tasks, like autonomous driving, here are a few hints you can start with:
- use a large frozen pretrained convolutional neural network without the last few layers as a pre-processor for raw frames. Or let it learn too, but lower the learning rate for its weights. This will require diving deeper into TensorFlow Documentation.
- feed more than 1 game frame as the observation to the network, potentially going into past exponentially (e.g. feed frames 0, -1, -3, -9, etc.)
- use GPUs or TPUs to train. High-resolution frames will require a lot of RAM.
- good luck!
Conclusion
Check out our cool products for developers.
See more of our C# Deep Learning Samples! Until the next time!